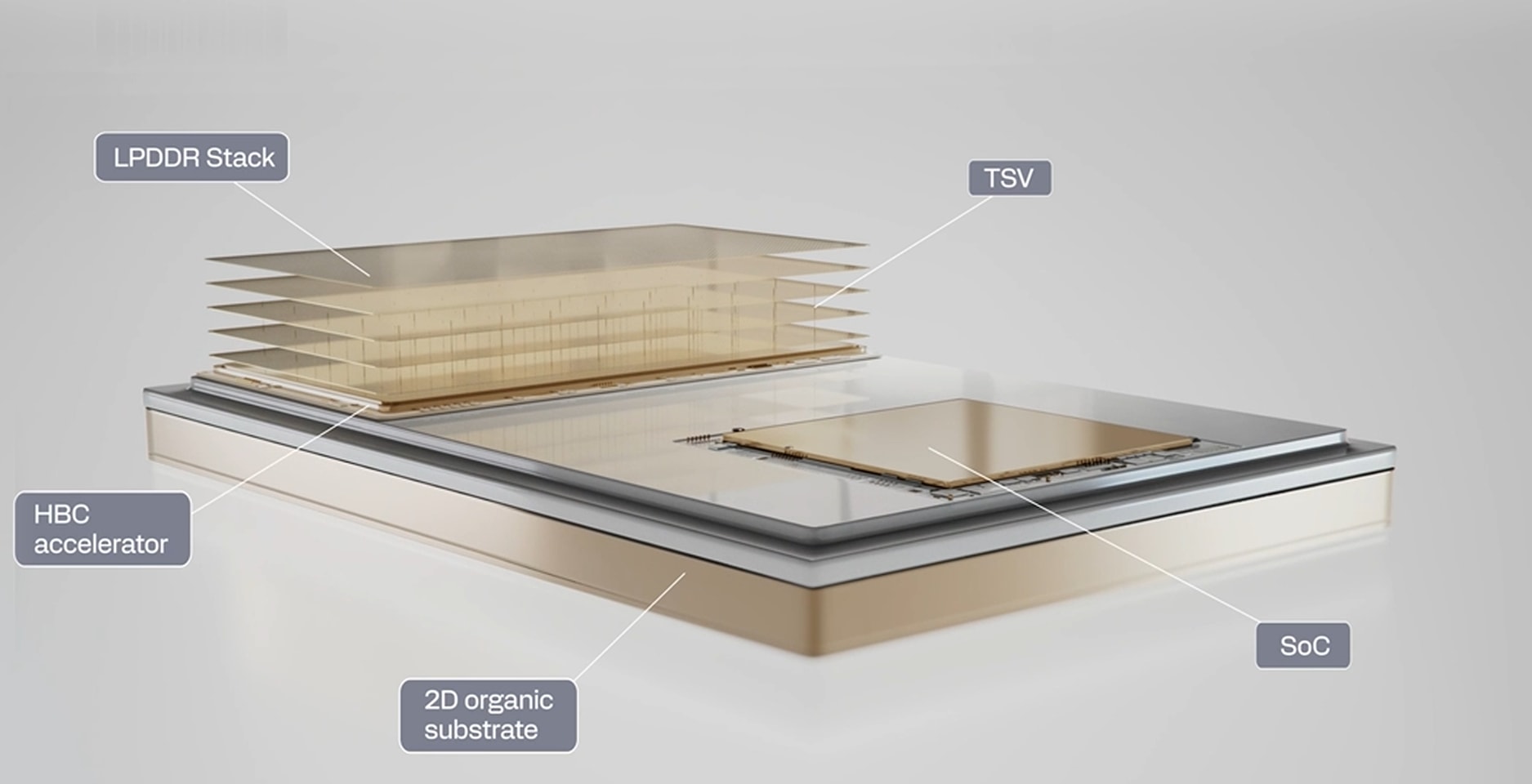
SpaceX has further expanded the availability of its Colossus 2 supercomputing cluster, adding 10,800 NVIDIA H100 GPUs to its already extensive rental pool. The move comes as Grok AI—developed internally at SpaceX—faces growing scrutiny over its infrastructure strategy, particularly regarding the practicality of a mixed-GPU architecture for large-scale AI training.
The Colossus 2 cluster, first announced in early 2024, was designed to complement the original Colossus 1 system. While Colossus 1 relied on a mix of H100 and A100 GPUs—an approach SpaceX described as a 'mish-mash' due to performance inconsistencies—the newer Colossus 2 cluster standardizes entirely on the H100, which offers up to 307 TFLOPS of AI-focused compute. This shift suggests an effort to address some of the operational challenges that plagued its predecessor.
Despite the upgrade, questions persist about whether a cluster built for flexibility is truly optimized for AI workloads. The H100's unified memory architecture and accelerated networking are critical for training large language models, but SpaceX's rental model—where capacity is leased out in blocks rather than per-GPU—introduces variables that could impact cost efficiency for tenants. For example, a tenant renting an entire node might find themselves paying for GPUs they don't need if the workload doesn’t fully utilize the cluster's peak performance.

Why the Expansion Matters
The addition of 10,800 H100 GPUs to Colossus 2 more than doubles SpaceX's total rental GPU capacity. This expansion is notable not just for its scale but also because it positions SpaceX as a direct competitor in the cloud AI market, where traditional providers like AWS and Google Cloud dominate. However, the lack of transparency around pricing and node allocation could make it difficult for smaller AI startups or research teams to integrate Colossus 2 into their workflows without significant upfront planning.
For Grok AI, the implications are twofold. On one hand, having direct access to a massive in-house cluster removes dependency on third-party cloud providers, potentially reducing operational costs. On the other, the rental model—where SpaceX retains ownership of the hardware—means Grok's growth is tied to SpaceX's willingness to expand capacity further. If demand for Grok outpaces the available Colossus 2 nodes, the project could face bottlenecks that limit its scalability.
Looking ahead, the biggest beneficiaries of this expansion will likely be AI researchers and small-to-mid-sized companies that can leverage SpaceX's cluster without the overhead of managing their own data centers. For larger enterprises or hyperscale players, the lack of fine-grained control over GPU allocation may prove to be a limiting factor compared to traditional cloud offerings.